Query then Fetch 와 DFS Query then Fetch를 주로 사용.
1. DFS Query then Fetch
Elastic Search에서 Default로 제공하는 검색(Search) 로직
- Query Phase : 인덱스를 구성하는 샤드들로부터 DOC들을 검색
- Fetch Phase : Query Phase에서 검색된 DOC들의 스코어를 정렬하여 응답할 DOC들을 선정하고 인덱스 샤드로 부터 실제 DOC 데이터를 추출
1-1. Example 1)
Cluster Environment
- 클러스터는 4개의 데이터 노드로 구성
- 검색 서비스를 제공하는 인덱스는 2개의 샤드(P0, P1)로 구성되어 Node 2, Node 4에 배치되어 있는 상황
- 현재 생성한 인덱스의 Replica는 없음
1-1-1. Query Phase
Step1.

Step 2.

1-1-2. Fetch Phase
Step 1.
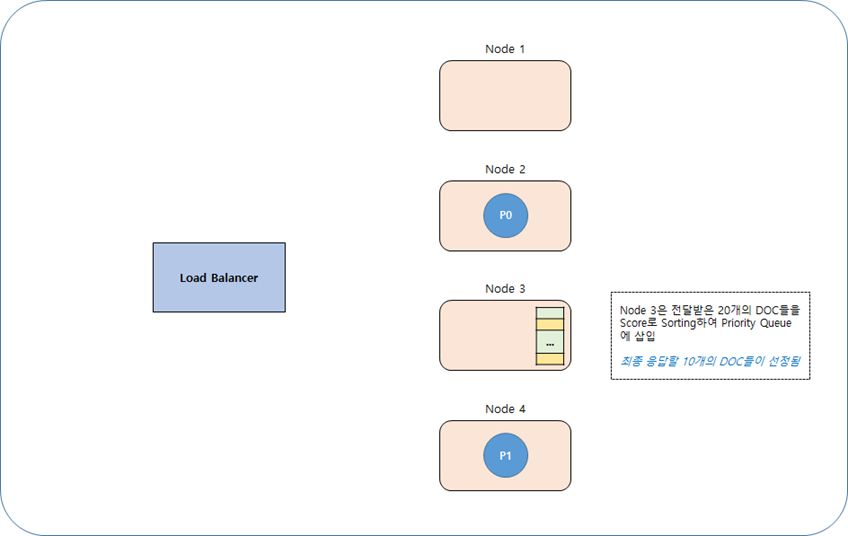
Step 2.

Step 3.

1-2. Example 2)
위 Example 1과 동일한 노드의 클러스터로 구성
인덱스를 구성하는 샤드 수는 2개로 같지만 Replica를 하나 생성하여 총 4개의 샤드((P0, P1, R0, R1)가 존재
· Step 1

· Step 2

· Step 1
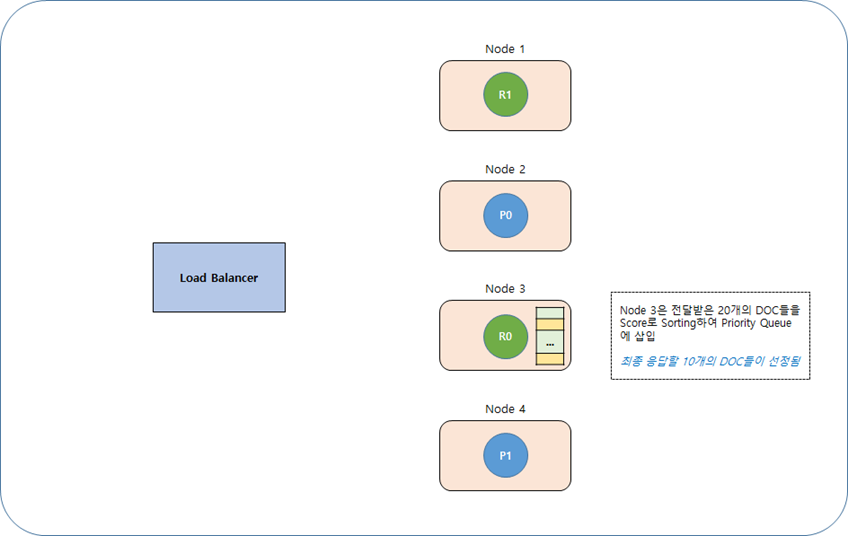
· Step 2
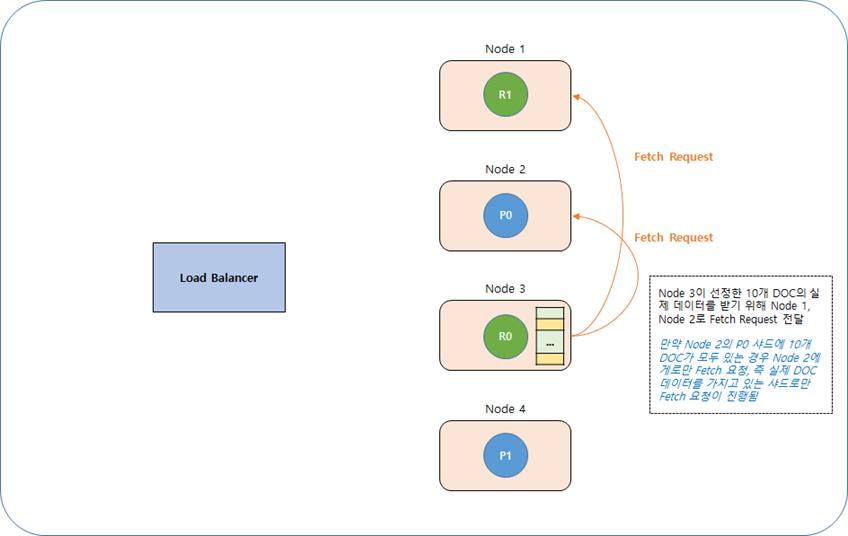
· Step 3

2. DFS Query then Fetch
기존 Query then Fetch의 경우 Query Phase에서 각 독립된 샤드로부터 Query가 진행
이에 복수의 샤드로 구성된 인덱스의 경우 각 샤드들이 포함한 DOC들의 상황에 따라 같은 DOC여도 스코어가 다를 수 있음
DFS(Distributed Frequency Statistics) Query then Fetch는 기존 Query then Fetch 로직 수행 전 모든 샤드에 Pre-Query를 진행하여 Global TF-IDF를 계산
Elasticsearch 관련 글)
https://jw92.tistory.com/5 설치 및 configuration (기본적인 설정)
https://jw92.tistory.com/6 vm.max_map_count 버그 해결
https://jw92.tistory.com/25 Indexing Process
https://jw92.tistory.com/26 Search Process
https://jw92.tistory.com/27 Indexing 방식 - Inverted Index
https://jw92.tistory.com/34 Indexing 파일 - Segment
'Elasticsearch (엘라스틱서치)' 카테고리의 다른 글
| Elasticsearch (엘라스틱서치)의 Indexing 파일 - Segment (0) | 2022.09.13 |
|---|---|
| Elasticsearch (엘라스틱서치)의 Indexing 방식 - Inverted Index (0) | 2022.09.02 |
| Elasticsearch (엘라스틱서치)의 Indexing Process (0) | 2022.09.02 |
| Elasticsearch (엘라스틱서치) vm.max_map_count 버그 해결 (0) | 2021.04.10 |
| Elasticsearch (엘라스틱서치) 시작하기 1. 설치 및 configuration (기본적인 설정) (0) | 2021.04.07 |