1. Segment
- 세그먼트는 Elastic Search(이하 ES)가 Lucene 라이브러리를 사용하여 생성하는 인덱싱 데이터의 단위로 복수 개의 파일로 구성
- 각 세그먼트들은 완전히 독립되어진 문서들의 집합이며 Inverted Index 구조로 생성된 실제 인덱싱 데이터로 구성되어짐
- 한번 생성된 세그먼트 파일은 수정이 불가능 (Immutability)

2. Segment File Path
아래 File Path에 인덱스 세그먼트 파일들이 위치
{data_path}/data/nodes/{node_num}/indices/{index_uuid}/{shard_num}/index/
| Name | Type | Description |
| {data_path} | String (Dir Path) | ES의 data를 저장하는 path |
| {node_num} | Integer (0 ~ ...) | 인스턴스에 속해있는 노드 번호 |
| {index_uuid} | String (UUID) | 인덱스의 UUID |
| {shard_num} | Integer (0 ~ ...) | 인덱스의 샤드 번호 |
3. Segment Naming
· Naming Format : "_" + "36진수{0-9,a-z}"
· Segment가 생성될 때 마다 아래와 같이 순차적으로 증가하며 Naming 적용
| _0 | _1 | _2 | ... | _9 | _a | ... | _z | _10 | ... | _9z | _a0 | ... | _az | ... |
4. Segment File 정보
4-1. Segment Files 예시
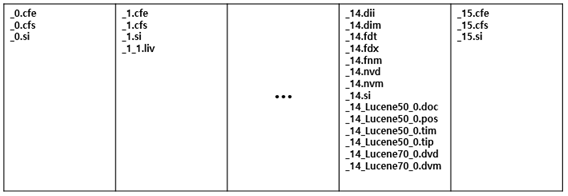
4-2. File Extension(확장자) 정보
| File Type | Extension | Generation Condition | Description |
| Segment Info | .si | Always | 세그먼트의 Metadata를 저장하는 파일 (e.g., OS, Java Ver., Lucene Format, ...) |
| Index Files | .fnm, .fdx, .fdt, .tim, .tip, .doc, .pos, ... | if (Segment Size >= 0.5Gb) | Index Field, Term Dictionary, Term Vector, Position 등의 인덱스 데이터 파일 |
| Compound Files | .cfs, cfe | if (Segment Size < 0.5Gb) | 해당 세그먼트의 모든 인덱스 데이터를 포함하는 Virtual 파일 |
| Live Documents | .liv | if (Deleted Documents) | Document의 Live 상태 정보 파일 |
| Commit Point | segments_N | Always | 세그먼트의 Commit Point 저장하는 파일 |
| Lock File | write.lock | Always | 인덱스의 동시 write를 방지하기 위해 사용되는 Lock 파일 |
5. Compound Files과 Live Documents
5-1. Compound Files
- 생성하는 세그먼트의 사이즈가 세그먼트 최대 사이즈(Default 5Gb)의 10%보다 작을 경우 해당 세그먼트는 Compound File로 저장
- 즉, Compound File로 저장하지 않는 세그먼트는 위 Main Extension에 기술된 Index Files 타입들(.fnm, .fdx, ...)로 저장
- ES가 참조하는 File Descriptor의 수를 줄이기 위한 것으로 Compound 포맷으로 생성된 세그먼트는 기본적으로 아래 예와 같이 3개의 파일로 구성
e.g., _4.si, _4.cfe, _4.cfs
5-2. Live Documents
기존 세그먼트의 DOC가 삭제되었거나 갱신되었을 경우 생성되는 파일
해당 파일은 삭제/수정된 DOC의 Live 상태를 0으로 Marking
5-2-1. DOC Deletion Scenario

1. "_4" 세그먼트에 포함된 일부 DOC가 삭제되었을 경우
→ "_4_1.liv"라는 파일을 새로 생성하여 삭제된 DOC의 ID를 0으로 Marking
2. 이후 "_4" 세그먼트에 포함된 다른 DOC가 삭제되었을 경우
→ 기존 "_4_1.liv" 파일 삭제 후 새로운 "_4_1.liv" 파일이 생성되며 기존 삭제된 DOC 및 신규 삭제된 DOC의 ID를 0으로 Marking
5-2-2. DOC Update Scenario

1. "_4" 세그먼트에 포함된 일부 DOC가 갱신되었을 경우
a. "_4_1.liv"라는 파일을 새로 생성하여 삭제된 DOC의 ID를 0으로 Marking
b. 수정된 DOC의 인덱스 데이터로 신규 세그먼트를 생성
(기존 마지막 세그먼트가 "_N-1"이면 "_N"이라는 이름의 세그먼트 생성)
6. Segment Merge
6-1. Summary
Elastic Search는 Background로 Merge Scheduler를 통해 기존 세그먼트들을 새로운 세그먼트로 병합(Merge)을 시도

Merge를 통하여 세그먼트들의 수를 줄이고 삭제된 문서들 또한 세그먼트에서 실질적인 제거가 가능함
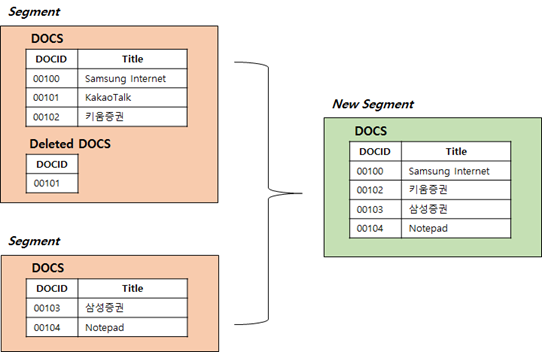
6-2. Tiered Merge Policy
- Elastic Search가 따르는 Lucene의 Segment Merge 정책
- Merge Scheduler에 의해 Trigger되며 샤드의 현재 세그먼트 정보를 바탕으로 Merge 수행 여부 판단 및 실행
- 주요 변수
- maxMergedSegmentBytes : 한 세그먼트가 가질 수 있는 최대 사이즈, Default 5Gb
- deletedPctAllowed : 삭제 문서 비율의 허용치, Default 33%
- 해당 Merge Policy의 기본적인 Merge Type 이름은 "NATURAL"로 아래 Step을 통해 Merge 수행 여부 판단 및 실행
6-2-1. Step 1
- 아래 조건에 해당하는 세그먼트를 선추출 → 추출된 세그먼트는 Merge 대상이 아님
- 세그먼트 사이즈가 2.5Gb(maxMergedSegmentBytes / 2)보다 크고, 총 삭제된 문서 비율이 33%(deletedPctAllowed) 이하인 경우
- 세그먼트 사이즈가 2.5Gb(maxMergedSegmentBytes / 2)보다 크고, 해당 세그먼트의 삭제된 문서 비율이 33%(deletedPctAllowed) 이하인 경우
6-2-1. Step 2
- 위에서 추출된 세그먼트를 제외한 나머지 세그먼트들을 대상으로 Total Size 및 최대 몇개의 세그먼트들을 가질 수 있는지(allowedSegCount) 계산

- e.g.,
- Total Size가 1.7Gb이면 총 28개의 세그먼트를 가질 수 있는 결과값이 추출 : (2Mb * 10) + (20Mb * 10) + (200Mb * 8)
- Total Size가 3.4Gb이면 총 31개의 세그먼트를 가질 수 있는 결과값이 추출 : (2Mb * 10) + (20Mb * 10) + (200Mb * 10) + (2Gb * 1)
- Total Size가 20Mb 이하인 경우는 결과값은 무조건 10
- 세그먼트들의 수가 최대 가질 수 있는 세그먼트 수(allowedSegCount)보다 클 경우 Merge를 수행
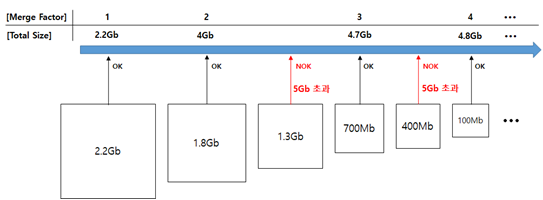
6-2-3. Step 3
- 사이즈가 큰 세그먼트를 우선으로 5Gb(maxMergedSegmentBytes)를 넘지 않는 조합으로 Merge를 수행
- 한번에 Merge 가능한 세그먼트의 수(Merge Factor)는 최대 10 (Default)
6-3. Force Merge
- Forcemerge는 강제로 세그먼트의 Merge를 수행하는 작업으로, Elastic Search에서 _forcemerge API를 통해 제공
- _forcemerge API 호출 시 파라미터가 명시되지 않으면 기본적인 Tiered Merge Policy의 "NATURAL"타입을 Trigger, 즉 큰 의미 없음
- Forcemerge 수행 시 큰 DISK I/O가 유발되기 때문에 Read/Write가 동시에 진행되는 인덱스에는 권장하지 않음
- _forcemerge API 주요 파라미터
- max_num_segments (Integer value)
- Merge를 통해 최종 생성할 세그먼트의 수
- e.g., max_num_segments가 1일 경우 모든 세그먼트들을 하나의 세그먼트로 병합
- only_expunge_deletes (Boolean value)
- 삭제된 문서가 일정 비율(default 10%)을 넘는 세그먼트를 대상으로 Merge 수행
- max_num_segments (Integer value)
Elasticsearch 관련 글)
https://jw92.tistory.com/5 설치 및 configuration (기본적인 설정)
https://jw92.tistory.com/6 vm.max_map_count 버그 해결
https://jw92.tistory.com/25 Indexing Process
https://jw92.tistory.com/26 Search Process
https://jw92.tistory.com/27 Indexing 방식 - Inverted Index
https://jw92.tistory.com/34 Indexing 파일 - Segment
'Elasticsearch (엘라스틱서치)' 카테고리의 다른 글
| Elasticsearch (엘라스틱서치)의 기본 랭킹 알고리즘 - BM25 (1) | 2024.09.05 |
|---|---|
| Elasticsearch (엘라스틱서치)의 Indexing 방식 - Inverted Index (0) | 2022.09.02 |
| Elasticsearch (엘라스틱서치)의 Search Process (0) | 2022.09.02 |
| Elasticsearch (엘라스틱서치)의 Indexing Process (0) | 2022.09.02 |
| Elasticsearch (엘라스틱서치) vm.max_map_count 버그 해결 (0) | 2021.04.10 |