개요
Recurrent Neural Network
- 기존의 뉴럴 네트워크는 과거의 데이터(아웃풋)가 미래에 영향을 줄 수 없는 구조
- Ex) 문장을 생성하는 모델, (1)The clouds (2)are (3)in (4)the sky
 기존의 Neural Network
기존의 Neural Network
- 시계열 데이터란 시간 축을 중심으로 현재 시간의 데이터가 앞, 뒤 시간의 데이터와 연관 관계를 가지고 있는 데이터를 의미
- RNN은 시계열 데이터 등의 맥락을 고려해 학습
- 이전 입력의 연산 결과가 현재 입력데이터와 함께 고려됨

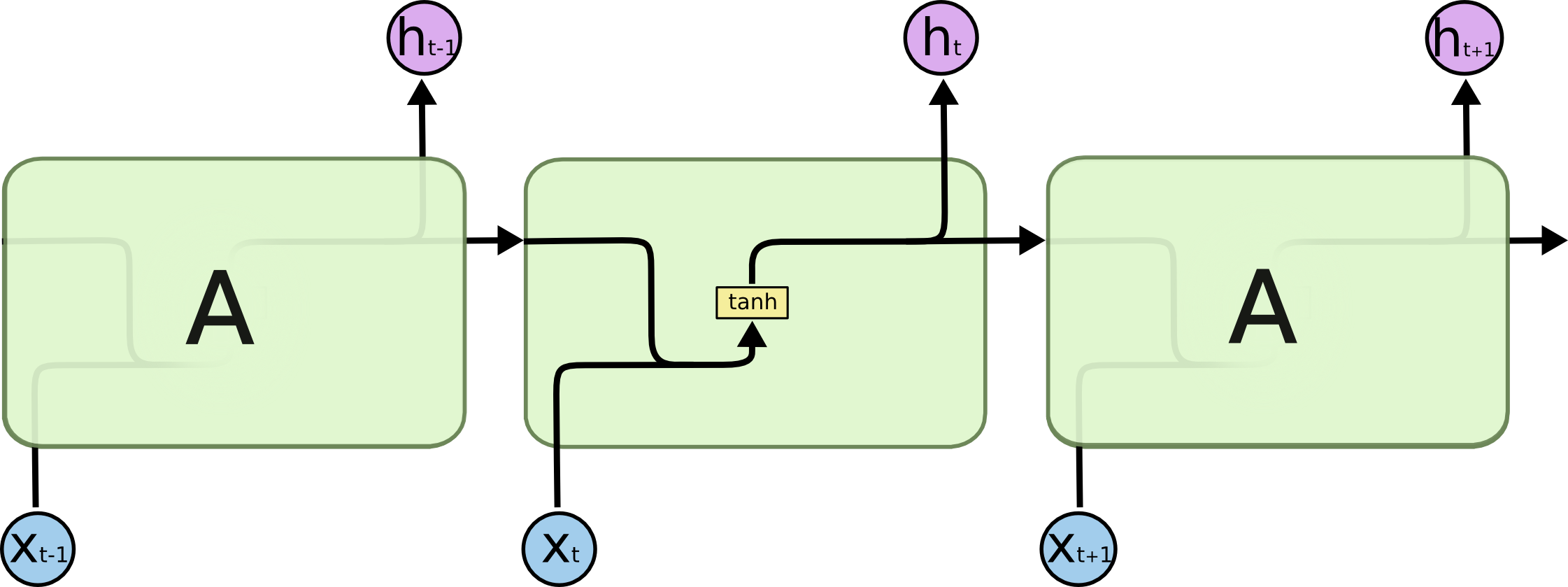
문제점
- RNN은 장기 의존성(Long Term Dependency) 문제를 가짐
- 짧은 기간에 의존하는 RNN은 과거 데이터를 기반으로 효율적으로 학습

- 더 많은 문맥을 필요로 하는 경우 학습하기가 매우 어려움 (Vanishing Gradient Problem)
- Ex) I grew up in Korea. ...(생략)... I speak fluent Korean

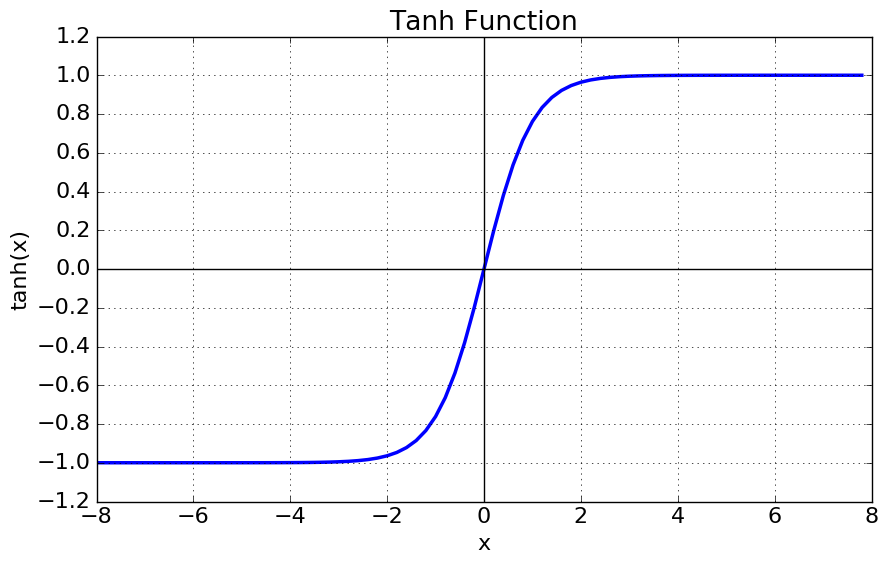
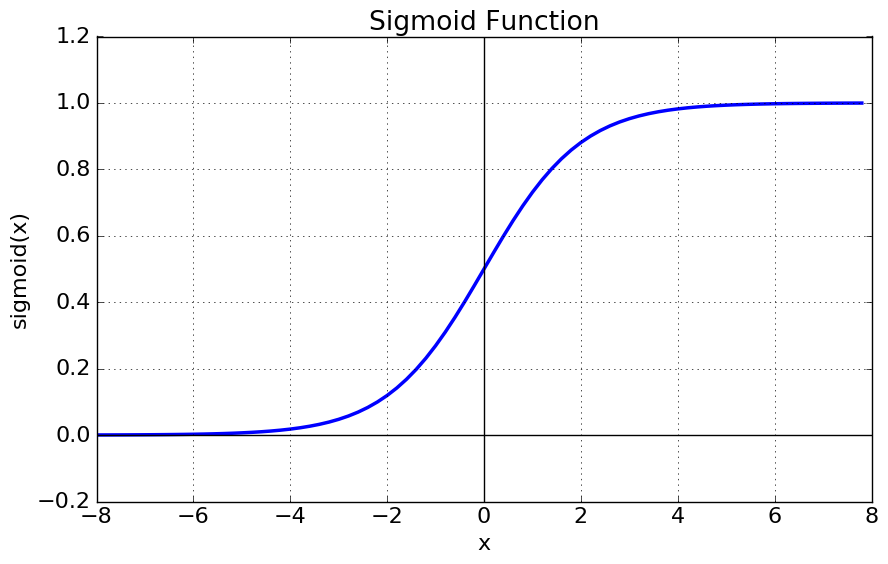
딥러닝에서 자주 쓰이는 tanh(RNN)와 sigmoid function.
h(h(h(h(h(h(h(h(x))))))): 1보다 작은 값이 계속 곱해져서 0으로 수렴 (1*0.8*0.8*0.8*0.8*0.8*0.8*0.8*0.8*0.8*0.8*0.8 = 0.08)

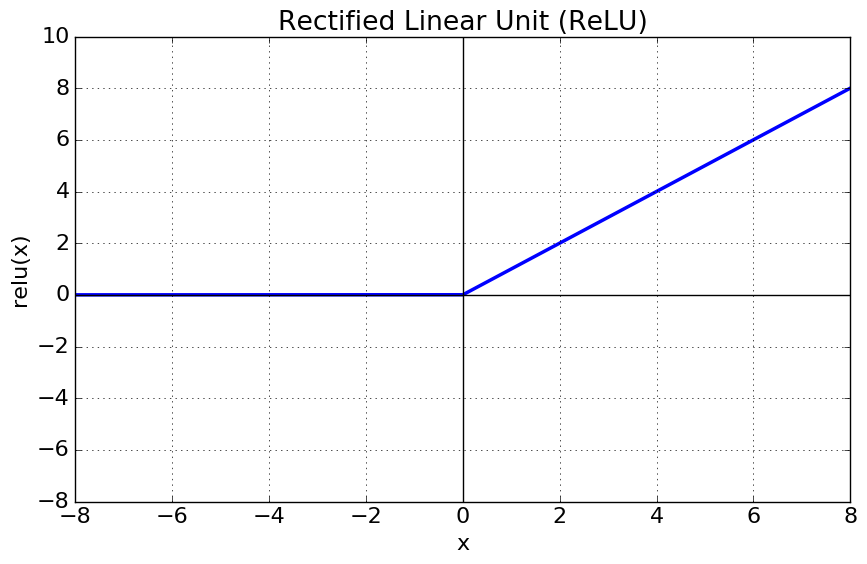
ReLU의 경우 vanishing gradient 문제는 해결하지만 히든레이어 값이 exploding 하기 때문에 사용하지 않는다
이러한 문제를 해결하기위해 LSTM이 등장
LSTM (Long Short-Term Memory)
기존 RNN( https://jw92.tistory.com/23 )의 문제점을 해결하기 위해 나온 것이 LSTM (Long Short-Term Memory) 1. 구조 LSTM의 핵심은 셀 스테이트(The cell state) 셀 스테이트는 아주 마이너한 계산을 거쳐 다..
jw92.tistory.com
'AI' 카테고리의 다른 글
| Universal Transformer (2018) (0) | 2022.09.04 |
|---|---|
| LLM - Transformer (2017) (0) | 2022.09.04 |
| Attention Mechanism (Dot-Product Attention) (2015) (0) | 2022.09.04 |
| Seq2Seq (Encoder-Decoder Model) (2014) (0) | 2022.09.04 |
| LSTM (Long Short-Term Memory) (0) | 2022.09.04 |