1. 전체 구조
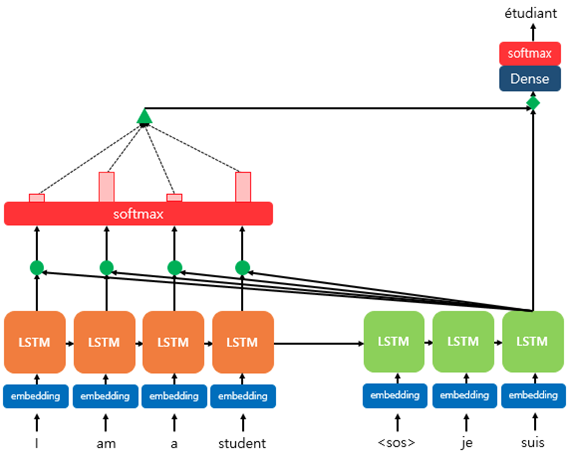
기존 Seq2Seq는 시점 t에서 출력 단어를 예측하기 위해서 디코더의 셀은 두 개의 입력값이 필요
여기에 하나의 값을 더해서 예측
a. 시점 t-1의 Hidden state
b. 시점 t-1에 나온 출력
c. 어텐션 값(Attention Value)
2. Attention Score
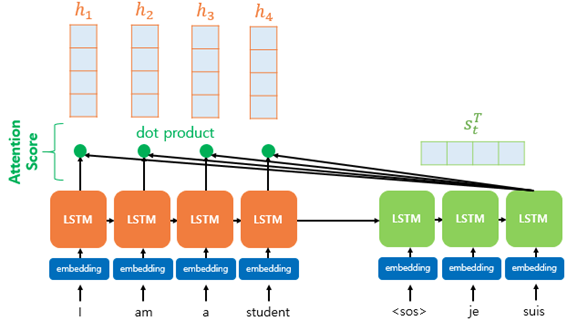
(<sos>, je는 같은 과정을 거쳐 현재 suis에 대해 진행한다고 가정)
어텐션 스코어란 현재 디코더의 시점 t에서 단어를 예측하기 위해,
인코더의 모든 Hidden state 각각이 디코더의 현 시점의 state와 얼마나 유사한지를 판단하는 스코어값
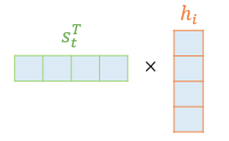
모든 Input hidden state에 대하여 아래와 같이 내적하여 값을 구함
3. Attention Distribution using Softmax
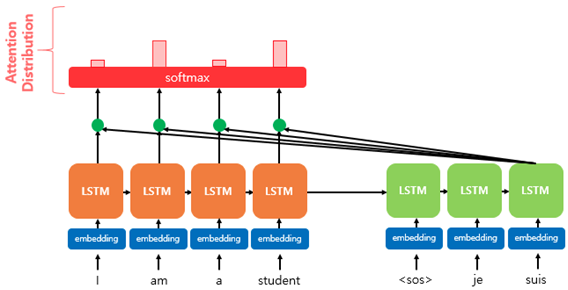
Softmax 함수를 활용하여 입력 시점마다 모든 값을 합하면 1이 되는 확률 분포를 얻어냄
4. Attention Value (Weighted Sum)

위에서 나온 확률 분포와 인코더의 모든 Hidden state를 이용하여 Attention Value 계산
5. Concatenate Attention value and Current state
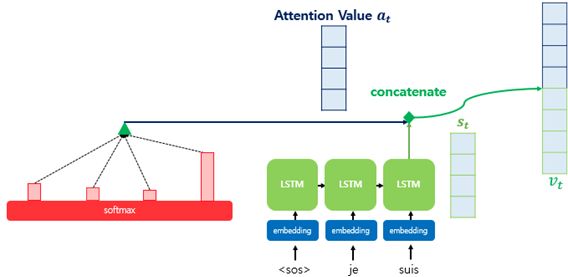
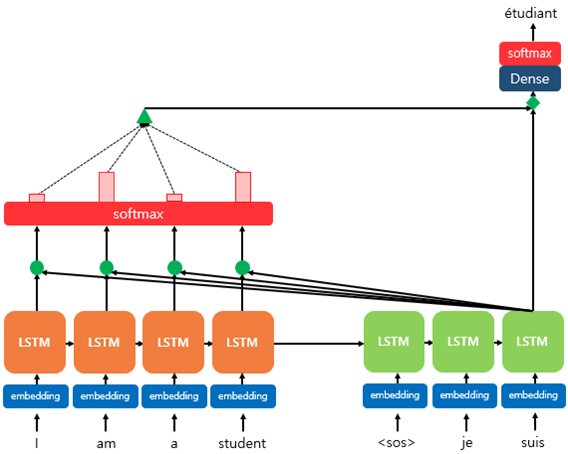
6. 위의 값을 Input으로 사용하여 출력을 구함
'AI' 카테고리의 다른 글
| Universal Transformer (2018) (0) | 2022.09.04 |
|---|---|
| LLM - Transformer (2017) (0) | 2022.09.04 |
| Seq2Seq (Encoder-Decoder Model) (2014) (0) | 2022.09.04 |
| LSTM (Long Short-Term Memory) (0) | 2022.09.04 |
| RNN (Recurrent Neural Network) (0) | 2022.01.12 |